




Kafka is a distributed streaming platform that is used to build real-time pipelines and streaming apps. It is a good replacement for a traditional message broker. For applications with large-scale message processing Kafka is the most preferred.
It is used by very large applications like twitter, LinkedIn, uber, etc. And Zookeeper is a centralized service that maintains configuration information, naming and provides the intention of this blog, how to set up a Kafka and Zookeeper multi-node cluster for the message streaming process.
If you want to implement high availability in a production environment, the Apache Kafka server cluster must consist of multiple servers.
For a cluster to be always up and running, the majority of the nodes in the cluster should be up. So, it is always recommended to run zookeeper cluster in the odd number of servers.
In this blog, I’ll set up a Kafka and zookeeper cluster with 3 nodes.
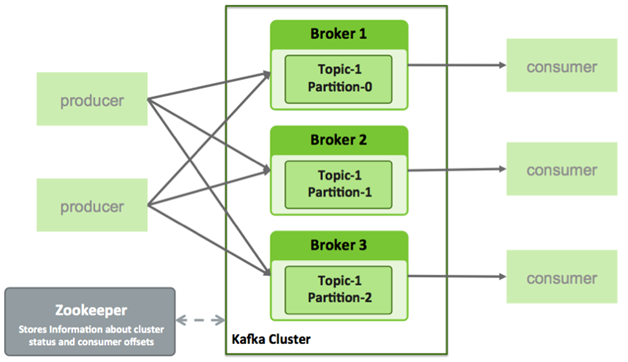
What is Kafka?
Kafka is used for building real-time data pipelines and streaming apps.
What is ZooKeeper?
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. All of these kinds of services are used in some form or another by distributed applications.
Prerequisites
- Install Java(Minimum 1.7)
- Kafka zookeeper binary files
Install Java
Install the java in all instances
In Ubuntu, Add the PPA using below command
nbsp;sudo add-apt-repository ppa:webupd8team/java ppa:webupd8team/java
Run commands to update system package index and install Java installer script:
nbsp;sudo apt-get update
nbsp;sudo apt-get install oracle-java8-installer
In CentOS,
$ yum install java-1.8.0-openjdk
check this version
$ java -version
Install Zookeeper
Download the Zookeeper binaries on your all instances and extract them.
$ wget http://mirror.cc.columbia.edu/pub/software/apache/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz
$ tar -xvf zookeeper-3.4.10.tar.gz
$ ln -sfn zookeeper-3.4.10 /opt/zookeeper
$ rm zookeeper-3.4.10.tar.gz
Install Kafka
Download the Kafka binaries on your all instances and extract them.
$ wget http://mirror.cc.columbia.edu/pub/software/apache/kafka/0.11.0.0/kafka_2.11-0.11.0.0.tgz
$ tar -xvf kafka_2.11-0.11.0.0.tgz
$ ln -sfn kafka_2.11-0.11.0.0 /opt/kafka
$ rm kafka_2.11-0.11.0.0.tgz
Update zookeeper properties
Create Zookeeper.properties file using the below command in all instances.
$ touch
/opt/zookeeper/conf/zookeeper.properties
And update the zookeeper.properties file with the below content in all instances.
dataDir=/tmp/zookeeper
clientPort=2181
maxClientCnxns=200
tickTime=2000
server.1=x.x.x.x:2888:3888
server.2=x.x.x.x:2888:3888
server.3=x.x.x.x:2888:3888
initLimit=20
syncLimit=10
- The value of dataDir with the directory where you would like ZooKeeper to save its data and log respectively.
- clientPort property, as the name suggests, is for the clients to connect to ZooKeeper Service.
- x in server.x denotes the id of Node. Each server.x row must have a unique id. Each server is assigned an id by creating a file named myid, one for each server, which resides in that server’s data directory, as specified by the configuration file parameter dataDir.
$ mkdir /tmp/zookeeper/ -p
$ touch /tmp/zookeeper/myid
$ echo '1' >> myid #Add Server ID for Respective Instances i.e. "server.1, server.2 and server.3"
Create myid file
- The ports, :2888:3888(Don’t change) that is at the end of the nodes. Zookeeper nodes will use these ports to connect the individual follower nodes to the leader nodes. The other port is used for leader election.
- And x.x.x.x is each node IP Address better to use private IP here. If you are trying to use public IP, Current node IP should be replaced with 0.0.0.0 in each node.
Update Kafka server properties
Update the Kafka server.properties file in all instances with the below content. This file is located in /opt/Kafka/config/server.properties
broker.id=1
# With the help of this we can consume outside of instance
advertised.host.name=x.x.x.x # current node public IP or hostname
# Enter the zookeeper quorum details as below
zookeeper.connect=x.x.x.x:2181,x.x.x.x:2181,x.x.x.x:2181
-
- The broker.id property is the unique and permanent name of each node in the cluster.
- advertised.host.name Hostname to publish to ZooKeeper for clients to use.
- zookeeper.connect Specifies the ZooKeeper connection string in the form hostname:port where the host (better to use private IP of each node) and port are the host and port of a ZooKeeper server.
Start the services
Before starting the Kafka service, start the zookeeper service using below command in all instances
$ /opt/zookeeper/bin/zkServer.sh start /opt/zookeeper/conf/zookeeper.properties
Check the zookeeper status using the below command. In these nodes, any of one zookeeper service will act as a leader remaining will be followers.
$ /opt/zookeeper/bin/zkServer.sh status
Start the Kafka service using below command in all instances
$ /opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties
Test the Services from Terminal
Create the topic using below command
$ /opt/kafka/bin/kafka-topics.sh --create --zookeeper x.x.x.x:2181,x.x.x.x:2181,x.x.x.x:2181 --replication-factor 1 --partitions 1 --topic sample_test
Get the list of topics using below command
$ /opt/kafka/bin/kafka-topics.sh --list --zookeeper x.x.x.x:2181,x.x.x.x:2181,x.x.x.x:2181
Consume the messages using below command
$ /opt/kafka/bin/kafka-console-consumer.sh --zookeeper x.x.x.x:2181,x.x.x.x:2181,x.x.x.x:2181 --topic sample_test --from-beginning
It will keep on listening, currently, there are messages on that topic.
Note: we have to use –zookeeper option with anyone or list of clustered node IP address’s or domains while creating topics, listing topics and consuming the message.
Produce the messages using the below command (open the new terminal and try it).
$ /opt/kafka/bin/kafka-console-producer.sh --broker-list x.x.x.x:9092,x.x.x.x:9092,x.x.x.x:9092 --topic sample_test
It will keep on listening, type the message and hit the enter and now check in previous consumer terminal.
It’s possible to test these operations from other systems (out of cluster nodes). if advertised.host.name property is configured by public IP in Kafka server properties. For more details about the Kafka and Zookeeper feel free to connect with us.
Don’t forget to subscribe to our weekly newsletters for more such goodies from our blog.
We provide DevOps consulting services to accelerate speed-to-market. Enable continuous delivery pipeline across cloud platforms for faster time-to-





