




Whenever we’re building a service-oriented product, it must be integrated with a collection of services like chat and payments, etc. So, it’s obvious that it might lead us to face any conflicts while integrating too many services at a time. This is where Kafka is being highly recommended to avoid any future conflicts while adding multiple services.
Let’s look at How Kafka and Kafka’s event-driven process will use and simplify the service-oriented architecture.
What Is Kafka?
Kafka is an open source framework that helps for storing, reading and analyzing the streaming data and it is written using Java and Scala.
Apache Kafka is a distributed platform that gives high scalability, fast and fault-tolerant messaging application to stream applications and data processing.
Kafka also has some key capability for handling the messages like below:
- Publish and Subscribe for record streaming. This is exactly the same as a traditional messaging system
- It will build the real-time streaming data pipelines based on the processed data in an application.
- It runs on one or more servers as a cluster.
- Each record has key, value, and timestamps.
Kafka Core APIs
- Producer API – used to allow an application to publish a stream of records.
- Consumer API – used to allow subscribe stream of records.
- Streams API – used to handle the streams between the input stream and output stream.
- Connector API – used for running or building reusable consumers and producers.
Kafka On Rails – How To Use Kafka In Rails
First, you can install Kafka in Rails using the below procedure.
Kafka Installation
Add this line to your application’s Gemfile:
gem ruby-kafka
And then execute:
$ bundle
Or install it yourself as:
$ gem install ruby-kafka
For setting Kafka in Rails, we have a gem called ruby-kafka this will help us to build a messaging service application with Kafka.
After Installation, we have to initialize ‘config/initializers/kafka_producer.rb’ this into our application.
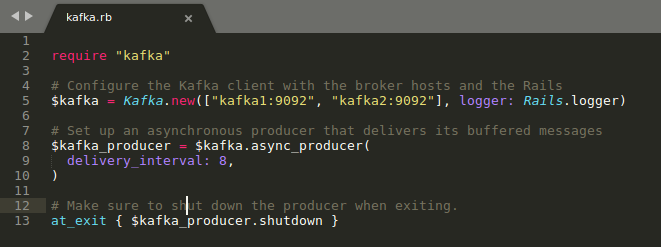
After initializing the Kafka, we can write the method for sending and receiving the message outside of the web execution thread and these events will take care of the asynchronous behavior of Kafka.
require "kafka" kafka = Kafka.new(["kafka1:9092", "kafka2:9092"], logger: Rails.logger) kafka_producer = kafka.async_producer( delivery_interval: 10, ) message = Message.create(params[:message]) kafka_producer.produce(message.to_json, topic: "sending_events", partition_key: current_user.id)

Above image shows how we have to produce the events in Kafka.
- The first param is event data in JSON format.
- Second param topic keyword refers to Kafka partition. This partition helps to find which Kafka broker is handling the data across multiple brokers as it can be helpful for application scalability and reliability.
- Third param is partition_key it helps to group all specific events together based on the process it involved.
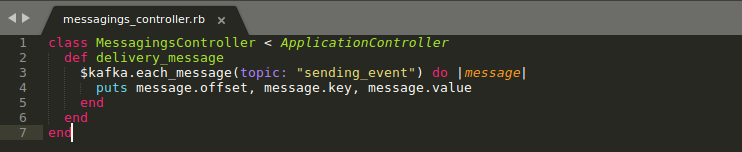
require "kafka" kafka = Kafka.new(["kafka1:9092", "kafka2:9092"], logger: Rails.logger) kafka.each_message(topic: 'sending_message') do |message| -- some process -- end
In the above image, you can see how we can receive the events from the servers. The method I have used here will only fetch events as a single partition once at a time. Also, if you want to fetch the multiple events from the different partitions(brokers) then you can use Consumer Groups for fetching all at once.
For example, The messaging system sends a message to the customer after getting the payment for the specific message based on the cost. As you can understand, here Kafka has to deal with two servicing now, one is Message service and the other one is Payment service so If any of the services fails then the streams of Kafka either upstream or downstream which will take care of the failed requests
Kafka has two types of a stream. One is upstream which is responsible for monitoring the event and the other one is called downstream which is responsible for identifying the service availability. Even when any services fails, Kafka will continue to consume the events. When there is a possibility of facing downstream service then it will continue processing the events and it will resume performing the service which failed.
Kafka Event Notification
Event Notification has four patterns. We can those look at below,
Event Notification:
After completing the process, upstream will send event notification, This event will have only minimum information like an event, timestamps(published_at), etc. If downstream really need more data then it will make a network call back upstream to retrieve it.
Event-Carried State Transfer:
Upstream sends the notification with additional data. So when the downstream consumer takes a local copy of the data, we no need to make a network call again to upstream.
Event-Sourcing
Event sourced will start capturing the data when the events start and it continues capturing until it processes with a database to rebuild the state of our application. Each and every process will be stored as a notification with an exact state of the process.
Parallely, This Event Sourcing ensures that all the changes to application state are stored as a sequence of events.
Command Query Responsibility Segregation:
The final one is CQRS- Command Query Responsibility Segregation which separates reading and writing events into different models. Either way, it makes sure the command should perform actions and the query to return data where one service will read the events and the other one will write the events.
For example,
In Database, the create and update queries take care of one service whereas the read-only queries take care of the other service. So, this way of handling separation reduces the complexity of event notification.
Also, keep a note to mind, here the commands will not have the rights to return the data and also the query cannot change the data.
Also read: Kafka And Zookeeper Multi Node Cluster Setup
Am done with explaining the major concepts of building service-oriented architecture using Kafka and Rails. Also would love to hear much of your thoughts & additional tips on it in the comment section below.
[contact-form-7 404 "Not Found"]





