





Apache Spark has gained immense popularity in the world of big data processing due to its speed, scalability, and versatility. Among its various components, Apache Spark SQL stands out as a powerful tool for data transformation and analysis. In this collaborative blog post, we will explore some advanced techniques for data transformation and analysis using Apache Spark SQL. We’ll cover various topics and provide code examples to help you harness the full potential of this amazing technology.
1. Setting up Apache Spark:
Before we dive into advanced data transformation and analysis, let’s ensure that we have Apache Spark set up. You can download Apache Spark from the official website (https://spark.apache.org/downloads.html) and follow the installation instructions for your platform.
2. Loading Data:
One of the first steps in any data analysis project is loading the data. Apache Spark SQL provides easy ways to load data from various sources like CSV, Parquet, JSON, and more. Let’s load a CSV file into a Data Frame:
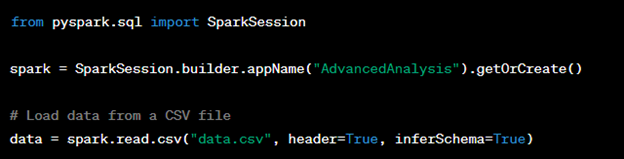
3. Data Exploration:
Now that we have our data loaded, let’s perform some basic exploration to understand its structure. We can use the printSchema() and show() methods to achieve this:
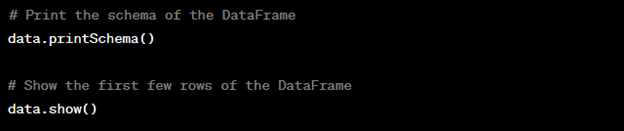
4. Filtering Data:
Filtering data is a fundamental operation in data analysis. Suppose we want to filter our data to include only records where the “age” column is greater than 30:

5. Aggregations:
Aggregations allow us to summarize data. Let’s calculate the average age for each gender:

6. Sorting Data:
Sorting data is often necessary for better visualization and analysis. We can sort our data by the “age” column in ascending order:
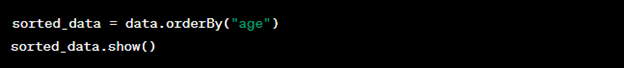
7. Joining DataFrames:
In real-world scenarios, data often comes from multiple sources. Let’s assume we have another DataFrame containing information about occupations and want to join it with our existing data:
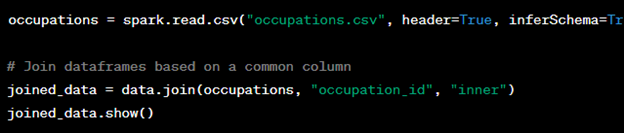
8. Window Functions:
Window functions enable advanced analytics like calculating running totals, ranking, and more. Let’s use a window function to rank individuals by their income:
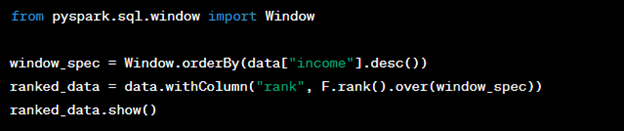
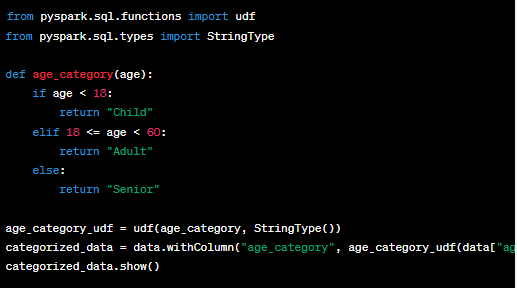
9. User-Defined Functions (UDFs):
Sometimes, we need to apply custom logic to our data. UDFs allow us to define custom functions and apply them to DataFrame columns. Let’s create a UDF to categorize individuals based on their age:
Conclusion:
Apache Spark SQL is a powerful tool for performing advanced data transformation and analysis tasks. In this collaborative blog post, we’ve explored various techniques, from data loading and filtering to aggregations, sorting, joining, window functions, and user-defined functions. These tools provide the foundation for tackling real-world data analysis challenges efficiently.
Looking for the right tech partner for performing advanced data transformation and analysis using Apache spark ? Agira Technologies would be your right choice, as we are working on providing the best big data solutions using Apache Spark technology. Just say “Hi” to us and let’s discuss this further.
