




Microservices architecture is very popular in recent days to build big systems/apps. However, in this architecture, the most common problem is how to manage distributed transactions across multiple microservices. Here is a brief article on my real-time experience through our client’s project, the actual problem and the possible solutions(patterns) that could solve it.
What is a distributed transaction?
When a monolithic application decomposes into microservice services, we have to break all transactions into distributed transaction. This means that all transactions in the monolithic system are now distributed into multiple services. Here is a customer order example with a monolithic system:
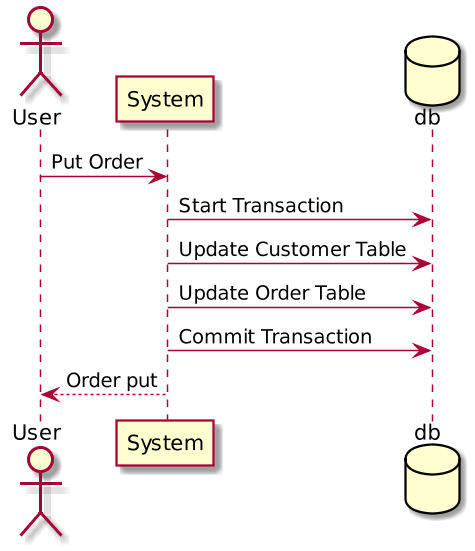 In the above example, if a user sends an Order action to a monolithic system, the system will create multiple database transactions that work over multiple database tables. If any step fails, the DB transaction can rollback. This is known as the ACID principle(Atomicity, Consistency, Isolation, Durability), which is guaranteed by the database system.
In the above example, if a user sends an Order action to a monolithic system, the system will create multiple database transactions that work over multiple database tables. If any step fails, the DB transaction can rollback. This is known as the ACID principle(Atomicity, Consistency, Isolation, Durability), which is guaranteed by the database system.
When decomposing this into microservice, we created 2 services i.e Customer Microservice and OrderMicroservice. Both of these have separate databases. Here is a customer order example with microservices:
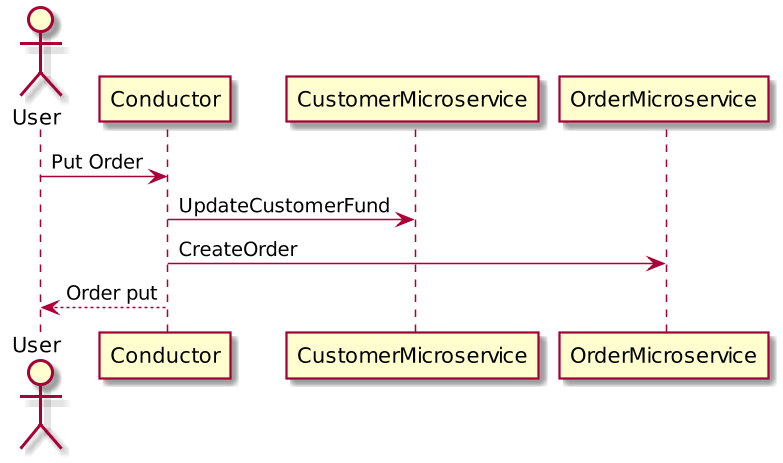
When an Order request comes from the user, both microservices will start to apply changes into their database. Because the transaction is now across multiple databases, it is now considered as a distributed transaction.
What are the Major Problems in Microservices?
In a monolithic system, we have a database system to ensure the ACID principle. But in microservice, we need to clarify the following key problems in ACIDity.
- Keep transactions atomic – In a database system, atomicity means that database operations are such that either all queries get complete, or nothing occurs. The microservice-based system does not have a global transaction coordinator by default. In the above example, if the CreateOrder method fails, how do we roll back the changes that we applied by the Customer Microservice?
- Keep transactions isolate – Before completing all the distributed transaction in microservice, if the user sends another request, should the object return old data or the updated one?. In the above example, Update Customer wallet succeeds. But it is still waiting for a response from CreateOrder service. Should requests for the current customer’s fund return the updated amount or not?
Ways to Solve the Major Microservices Problems
The following two patterns can resolve the above problem:
- Two-phase commit pattern
- Saga(3PC) pattern
Two-phase commit(2PC) pattern:
2PC has two phases: Prepare and Commit phase. In the prepare phase, all the microservices will ask you to prepare for some data change that could be done atomically. Once all microservices are prepared for data change, the commit phase will ask all the microservices to make the actual changes in DB.
Normally, 2pc needs one global coordinator which takes care of Prepare and Commit phases across multiple services. Here is a 2PC implementation for the customer order example:
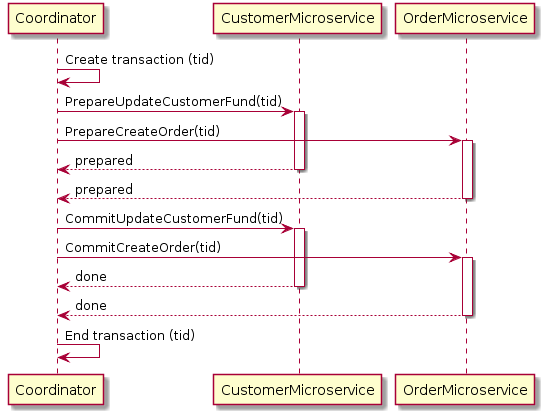
In the above example, when a user sends an order request, the Coordinator will first create a global transaction with all information. Then, it will ask the Customer microservice to prepare for updating a customer fund with the created transaction i.e the Customer microservice will then check if the customer has enough funds to proceed with the transaction. Once the Customer microservice is ready to perform the change, it will lock down the DB records from further changes and tell the Coordinator that it is prepared. The same thing happens for the order in the Order microservice. Once the Coordinator has confirmed all microservices are ready to apply their DB changes, then it will ask them to apply their changes by requesting a commit with the transaction. Once both phases are completed, records will be unlocked.
In the above process, if we get any failure at any point of time, the Coordinator will abort the transactions and start the rollback process. Here is a diagram of a 2PC rollback for the customer order example:
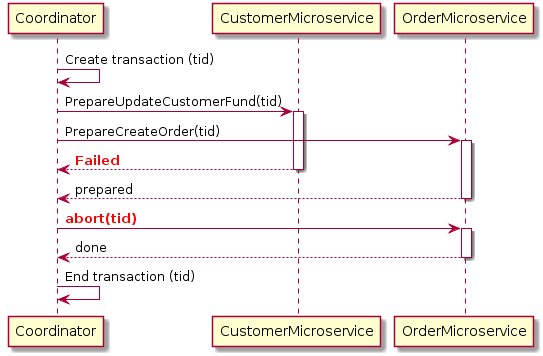 In the above sequence diagram, the Customer microservice fails to prepare for some reason, but the Order microservice prepares to create the order. The Coordinator will ask to abort all the prepared transactions i.e roll back changes and unlock the records.
In the above sequence diagram, the Customer microservice fails to prepare for some reason, but the Order microservice prepares to create the order. The Coordinator will ask to abort all the prepared transactions i.e roll back changes and unlock the records.
Advantages of 2PC:
Using 2PC, we achieved all ACID principles.
- More atomic(A)
- Data consistency(C)
- Read-write Isolation(I)
- Durability(D)
Disadvantages of 2PC:
- Request is synchronous (blocking)
- Lock records/object until transaction completes
- Possibility of Deadlock between transactions
The above drawback may lead to system performance bottleneck too.
SAGA(3PC) pattern:
The Saga pattern is another widely used pattern for distributed transactions. The Saga pattern is asynchronous and more reactive. In this pattern, all the distributed transaction is completely asynchronous i.e we have to use AMQP such as RabbitMq, Kafka, etc. So the microservices communicate with each other through an event. If you want to know more about the event bus, please refer to our blog on rabbitMQ.
Here is a diagram of the Saga pattern for the customer order example:
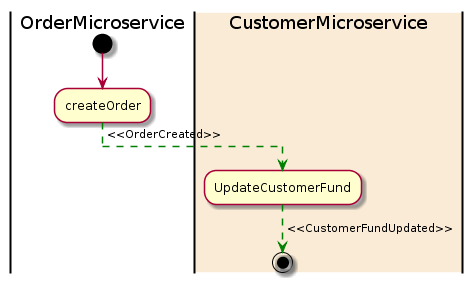
In the example above, the Order Microservice receives a request to place an order. Firstly, it starts to create an order and then emits an OrderCreated event. The CustomerMicroservice listens for this (OrderCreated)event and updates a customer fund once the event is received. If the amount is successfully deducted, then it will emit a CustomerFundUpdated event, which is the end of the transaction.
If any microservice fails to complete its transaction, the other microservices will begin to run compensation transactions event i.e to roll back the changes. So we call this pattern as 3 phase commit. Here is a diagram of the Saga pattern for a compensation transaction:
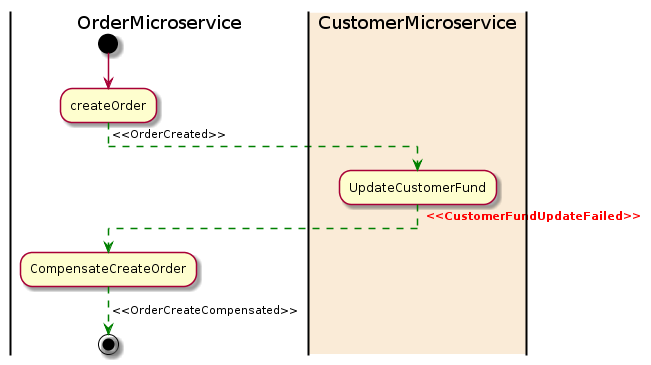 In the example above, the Update Customer Fund is failed for some reason and it then emitted compensated event i.e CustomerFundUpdateFailed event. The Order Microservice listens this the event and starts to revert the order which was created earlier.
In the example above, the Update Customer Fund is failed for some reason and it then emitted compensated event i.e CustomerFundUpdateFailed event. The Order Microservice listens this the event and starts to revert the order which was created earlier.
Advantages of the Saga pattern
- Data reliability and Long-lived transactions
- Request are asynchronous
- No lock for DB object
Disadvantages of the Saga pattern
- Difficult to debug/test especially if we have multiple microservices
- it does not have read isolation i.e user can see the order created but in next second, the order is removed due to failure transaction
Conclusion
The Saga pattern is the most preferable way of solving distributed transaction problems for a microservice-based architecture. As a team if we have to adopt the Saga pattern, it requires a change in mindset for both development and testing. Sometimes It could be a challenge for a team that is not familiar with this pattern. Therefore, it is very important to choose the proper way to implement it for a project.
Read more interesting blogs related to Microservices such as Monolithic vs Microlithic architecture, Message queues in golang RabbitMQ, Building service oriented architecture using rails and kafka





